2023. 5. 11. 17:03ㆍ개발을 파헤치다/서버 인프라
데이터 조회는 DB를 사용할 때 아주 기본적인 기능이라고 할 수 있습니다.
어떤 방식으로 데이터를 조회하느냐에 따라 성능이 달라지고 그만큼 서비스 질이 좌우되기도 하죠. 당연히 서비스 입장에서는 가능한 한 빨리 원하는 데이터를 찾아서 유저에게 보여주는 것이 좋습니다.
DynamoDB는 I/O 성능과 확장성에 이점이 있는 데이터베이스인데요.
이것도 특성을 제대로 알고 사용한다는 전제하에 의미가 있는 말입니다.
Dynamo에서는 데이터 조회를 위해 두 가지 방식을 제공합니다.
바로 Scan과 Query입니다. Scan과 Query 모두 item collection을 가져오기 위한 기능이지만 동작 방식은 상당히 다릅니다. 제대로 알
고 사용하느냐 마느냐에 따라 매우 큰 성능차이가 발생할 수 있습니다.
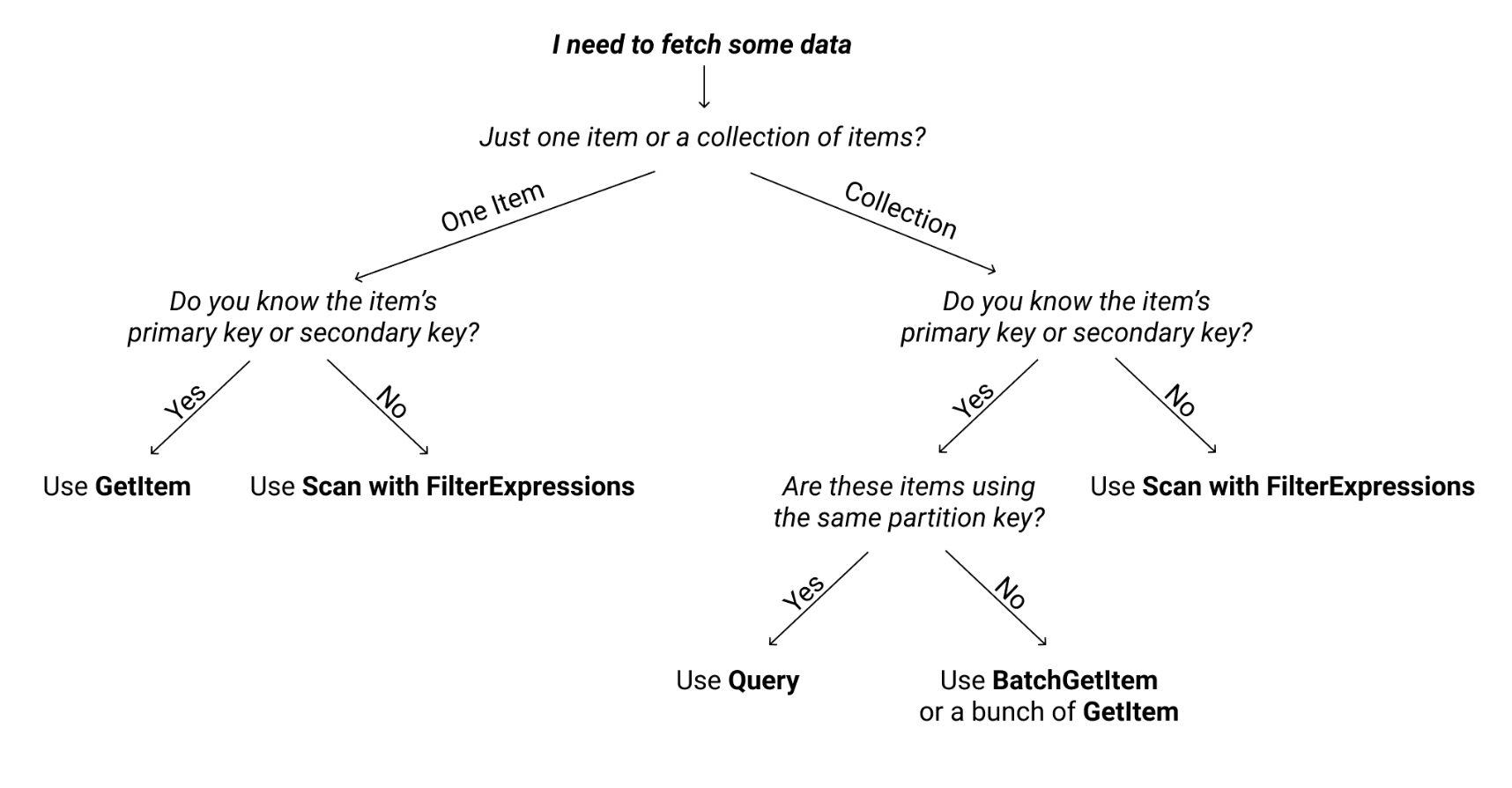
위 그림은 Dynamo를 사용해서 아이템을 가져오고 싶을 때 다양한 시나리오 중에서 어떤 방식을 쓰면 좋을지 나타낸 것인데요. 여기에서 Scan과 Query의 차이점을 알 수 있습니다.
Scan은 일치하는 요소를 찾기 위해 전체 테이블을 조회하는 것입니다. 그래서 primary key나 secondary key 값이 없을 때 사용하죠. Dynamo는 파티션키와 범위키 두 가지를 통해 기본키를 정하는데요. 이 키값마저 모를 때 사용하는 것이 Scan입니다. 상당히 리소스가 많이 드는 방식이라 가능하면 사용하지 않는 게 좋겠죠. 특히 사용자가 요청하는 API에서는 Scan을 쓰는 것을 최대한 피해야 합니다. 이런 리소스 많이 먹는 요청이 동시다발적으로 들어오면 성능이 엄청 안 좋아질 테니깐요.
Query의 경우 primary key나 secondary key값을 가지고 조회를 하기 때문에 훨씬 빠르게 찾아낼 수 있습니다. 도서관에서 책을 찾는다고 가정해 보죠. 도서관에는 정말 수많은 책들이 있습니다. Scan을 통해서 책을 찾는다는 것은 책 제목을 가지고 전체 도서관을 뒤지는 것을 의미합니다. 정말 오래 걸리겠죠? 하지만 Query로 찾게 된다면 지정된 구역의 몇 번째 칸이라는 정보를 알고서 찾는 것과 같습니다. 뒤져야 할 가짓수가 훨씬 적어져서 빠르게 찾을 수 있죠. 이런 특징 때문에 Query를 쓰려면 반드시 index가 설정이 되어있어야 합니다.
위 그림에서 사용하는 GetItem이나 BatchGetItem 역시 Query와 마찬가지로 key값을 알고 있기 때문에 더 빠르게 아이템을 가져올 수 있습니다. 결국 key값을 알고 있느냐 없느냐로 Scan이냐 Query냐가 결정되는 것이죠.
따라서 DynamoDB를 설계할 때 index를 잘 설정하는 것이 매우 중요합니다.
'개발을 파헤치다 > 서버 인프라' 카테고리의 다른 글
| [AWS Event Bridge] AWS에서 간단하게 Scheduler 사용하는 방법 (0) | 2023.07.03 |
|---|---|
| [AWS] SAM(Serverless Application Model)에 새로운 Lambda Layer 추가하는 방법 (feat. 초보자도 쌉가능) (0) | 2023.05.12 |
| [AWS DynamoDB] PynamoDB 기본 사용법 정리(CRUD) (0) | 2023.05.08 |
| [AWS LightSail] LightSail에 5분만에 SSL 인증서 적용하는 방법 (이거보다 쉬운거 없음!!!) (0) | 2023.05.04 |
| [AWS S3] S3 Life Cycle 설정으로 비용 절감하는 방법 (0) | 2023.05.03 |